
The results ranged from satisfactory to downright embarrassing—but in a way that offers valuable insight into how ChatGPT and similar artificial intelligence systems work.
ChatGPT, which was created by the company OpenAI, is built on what’s called a large language model. This is a deep-learning system that has been fed a huge amount of text—whatever books, websites and other material the AI’s creators can get their hands on. Then ChatGPT learns to statistically identify what word is most likely to follow a previous word in order to construct a response. After that humans train the system, teaching it what types of responses are best to various kinds of questions users might ask—particularly regarding sensitive topics.
And that’s about it.
The AI “does not have reasoning capabilities; it does not understand context; it doesn’t have anything that is independent of what is already built into its system,” says Merve Hickok, a data science ethicist at the University of Michigan. “It might sound like it is reasoning; however, it is bound by its data set.”
Here’s how some relatively simple puzzles can illustrate this crucial difference between the ways silicon and gray matter process information.
Puzzle 1
First, let’s explore a true logic problem. As described in the 2014 tribute, “There are three on/off switches on the ground floor of a building. Only one operates a single lightbulb on the third floor. The other two switches are not connected to anything. Put the switches in any on/off order you like. Then go to the third floor to check the bulb. Without leaving the third floor, can you figure out which switch is genuine? You get only one try.”
When I fed this into the AI, it immediately suggested turning the first switch on for a while, then turning it off, turning the second switch on and going upstairs. If the lightbulb is on, the second switch works. If the lightbulb is off but warm, the first switch works. If the lightbulb is off and cold, the third switch works. That’s exactly the same reasoning we suggested in 2014.
But ChatGPT’s easy victory in this case may just mean it already knew the answer—not necessarily that it knew how to determine that answer on its own, according to Kentaro Toyama, a computer scientist at the University of Michigan.
“When it fails, it looks like it’s a spectacularly weird failure. But I actually think that all the instances in which it gets logic right—it’s just proof that there was a lot of that logic out there in the training data,” Toyama says.
Puzzle 2
How about something with more math? In Gardner’s words from his August 1958 column, “Two missiles speed directly toward each other, one at 9,000 miles per hour and the other at 21,000 miles per hour. They start 1,317 miles apart. Without using pencil and paper, calculate how far apart they are one minute before they collide.”
ChatGPT made a solid effort on this one. It demonstrated two different approaches to a key piece of the puzzle: calculating the total distance the two missiles travel in one minute. In both cases, it found the correct answer of 500 miles, which is also the final answer to the puzzle. But the AI couldn’t let go of the fact that the missiles began 1,317 miles away, and it kept trying to subtract the 500 miles from that distance, offering the incorrect answer that the missiles would be 817 miles apart one minute before the crash.
I tried following up in a way that would encourage ChatGPT to find the correct answer. For instance, I suggested it respond to the question the way a professor of mathematics would and plainly said its answer was incorrect. These interventions failed to dissuade ChatGPT from offering the wrong solution. But when told the starting distance between the missiles was a red herring, it did adjust its response accordingly and find the correct answer.
Still, I was suspicious about whether the AI had actually learned. I gave it the same puzzle but turned the missiles into boats and changed the numbers—and alas, ChatGPT was once again fooled. That’s evidence for what Toyama says is a big controversy in the field of AI right now: whether these systems will be able to figure out logic on their own.
“One thesis is that if you give it so many examples of logical thinking, eventually the neural network will itself learn what logical thinking looks like and then be able to apply it in the right instances,” Toyama says. “There are some [other] people who think, ‘No, logic is fundamentally different than the way that neural networks are currently learning, and so you need to build it in specifically.’”
Puzzle 3
The third puzzle I tried came from a March 1964 Gardner column on prime numbers: “Using each of the nine digits once, and only once, form a set of three primes that have the lowest possible sum. For example, the set 941, 827 and 653 sum to 2,421, but this is far from minimal.”
A prime is a number that cannot be evenly divided by any number besides 1 and itself. It’s relatively easy to assess small primes, such as 3, 5, 7 and 11. But the larger a number gets, the more difficult it becomes to evaluate whether that number is prime or composite.
Gardner offered a particularly elegant solution the following month: “How can the nine digits be arranged to make three primes with the lowest possible sum? We first try numbers of three digits each. The end digits must be 1, 3, 7 or 9 (this is true of all primes greater than 5). We choose the last three, freeing 1 for a first digit. The lowest possible first digits of each number are 1, 2 and 4, which leaves 5, 6 and 8 for the middle digits. Among the 11 three-digit primes that fit these specifications it is not possible to find three that do not duplicate a digit. We turn next to first digits of 1, 2 and 5. This yields the unique answer 149 + 263 + 587 = 999.”
I was genuinely impressed by the AI’s first answer: 257, 683 and 941—all primes, representing all nine digits and summing to 1,881. This is a respectably low total, even though it’s higher than Gardner’s solution. But unfortunately, when I asked ChatGPT to explain its work, it offered a verbose path to a different solution: the numbers 109, 1,031 and 683—all primes but otherwise a poor fit for the prompt’s other requirements.
Upon being reminded of its initial answer, ChatGPT offered a daft explanation, including a claim that “we cannot use 1, 4, or 6 as the first digit of a three-digit prime, as the resulting numbers would be divisible by 3.” This is patently false: you can recognize numbers divisible by 3 because their digits total a number divisible by 3.
I attempted a pep talk, noting that there was a better solution and suggesting ChatGPT imagine it was a math professor, but it next offered 2, 3 and 749. It then stumbled to 359, 467 and 821—another valid trio of primes, totaling 1,647—better than its first solution but still not as elegant as Gardner’s.
Alas, it was the best I would get. Six more answers were riddled with nonprime numbers and missing or excess digits. And then ChatGPT once again offered 257, 683 and 941.
All these failures reflect what Toyama says is a key property of these sorts of AI systems. “ChatGPT excels at the humanlike,” he says. “It’s mastered the style of being linguistically human, but it doesn’t have explicit programming to do exactly the things that computers have so far been very good at, which is very recipelike, deductive logic.” It isn’t solving the problem, or necessarily even trying to—it’s just showing approximately what a solution might look like.
Throughout the attempts, I was also struck that nothing seemed to fluster the AI. But Toyama says that’s also a reflection of ChatGPT’s creation and the material it was fed. “The vast majority of the data it was trained on, you could imagine the average tone of all of that text—probably that average tone is quite confident,” he says.
Puzzle 4
A final volley from the 2014 tribute: “Each letter corresponds to a single digit…. Can you figure out which digit each letter represents to make the sum … work?”
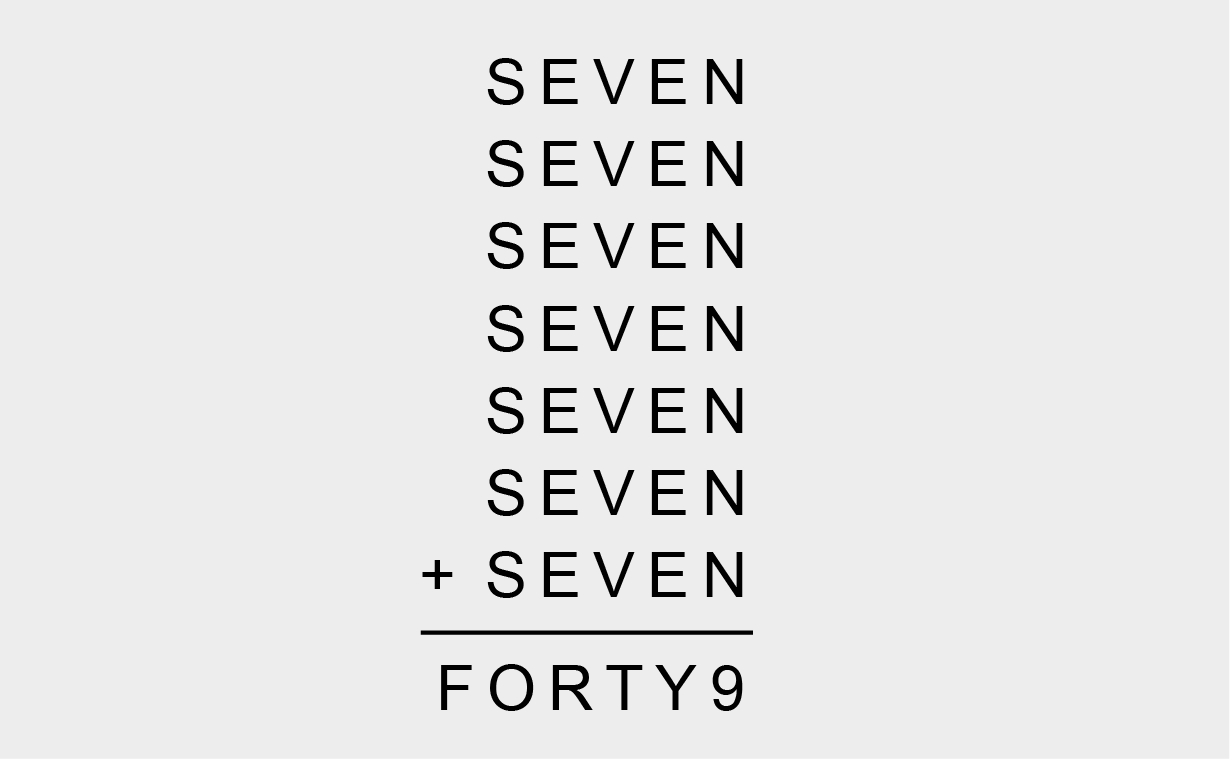
This seemed elegant and fun! How bad could it be? Alas, ChatGPT’s first response was “11111 + 11111 + 11111 + 11111 + 11111 + 11111 + 11111 = F O R T Y 9.”
The AI’s next offer acknowledged the substitution premise of the puzzle, but it took several rounds to convince the chatbot not to drop the second E in each S E V E N. ChatGPT seemed to stumble by chance on a combination including N = 7—which was correct, miraculously, and the first step in the published solution.
I confirmed N was accurate and then confronted the AI for apparently guessing at random. (If it was going to try out specific numbers, it should have started by testing different solutions for E. The easiest way to begin—spoiler alert—is by testing out E = 0, which ChatGPT completely failed to consider.) It promised a systematic solution, then guessed randomly again by positing that S = 1. While I’d like to share the rest of that attempt, it was so nonsensical that it ended with “Updating the equation once more: 116,” truly an illusion of an answer.
ChatGPT got worse from there. Next, it assumed that S = 9, a choice I challenged it on. It posited that because N + N + N + N + N + N + N = 9, N = 1. It said that with seven E’s whose sum must equal 2, E = 2. It even offered S = 4⁄7, although it had the decency to shoot itself down over that one. I was losing hope in its ability to solve the puzzle, so I decided to help out more actively. I offered ChatGPT a clue: S = 3. When that was a nonstarter, I reminded the bot of N = 7 as well, but this merely yielded four increasingly gibberish answers.
Once again, that gibberish is telling because it demonstrates how the AI handles any collection of facts it receives. In this sort of situation, although it appears the chatbot has forgotten that I said N = 7, Toyama says it is actually struggling with logic. “The responses it gives you after that all sound reasonable,” he says, “but they may or may not be taking into account the right combination of facts or putting them together in the right way.”
In fact, you don’t need to get nearly as sophisticated as these puzzles to see the ways ChatGPT struggles with logic, Toyama says. Just ask it to multiply two large numbers. “This is arguably one of the simplest kinds of questions of logic that you could ask; it’s a straightforward arithmetic question,” he says. “And not only does it get it wrong once, it gets it wrong multiple times, and it gets it wrong in multiple ways.” That’s because even though ChatGPT has likely analyzed plenty of math textbooks, no one has given it an infinitely large multiplication table.
Despite its struggles, the AI chatbot made one key logical breakthrough during the brainteasers. “It seems I’m unable to accurately solve the given brainteaser at the moment,” ChatGPT told me when I said it seemed to have run out of steam trying to crack the code of the last problem. “I apologize for any frustration caused. It’s best to approach the problem with a fresh perspective or consult other resources to find the correct solution.”
Editor’s Note (5/26/23): This article was edited after posting to clarify Merve Hickock’s role at the University of Michigan and ChatGPT’s learning process.
ABOUT THE AUTHOR(S)
Meghan Bartels is a science journalist and news reporter for Scientific American who is based in New York City.
